Future of Generative AI: Going beyond Text to Image
Introduction
Generative AI has made significant progress in recent years, particularly in the field of text-to-image generation. With the release of Stable Diffusion, and efficient fine-tuning procedures like LoRA, QLoRA, GLoRA etc, People have been able to create Text-to-Image Models very easily using their consumer level graphic cards. The development of highly efficient inference engines like VoltaML has also helped people deploy these models with ease. However, the potential of generative AI extends far beyond this specific application. In this blog, we will delve into the future of generative AI and explore the exciting possibilities that lie ahead.
Text-to- Well.. Image Actually
I know, I know, I said that we will be looking at what is there beyond text-to-image, but just bear with me for a second and look at these amazing, and innovative applications of text-to-image!


Yes, Now you can generate fully functional Aesthetic QR Codes! The introduction of aesthetic QR codes brings a new dimension of creativity and visual appeal to the world of QR code technology. These visually captivating codes allow individuals and businesses to design QR codes that are not only functional but also serve as beautiful pieces of art. By incorporating colors, patterns, and images, aesthetic QR codes open up exciting avenues for artistic expression, communication, and storytelling.

AI can now Generate Hands! SDXL 0.9
The field of generative AI continues to evolve rapidly, and the recent announcement of SDXL 0.9 has created quite a buzz in the community. SDXL 0.9 is a significant leap forward in terms of size and capabilities compared to its predecessors. This new version boasts larger image generation capabilities, allowing for the creation of high-resolution images up to 1024x1024 pixels. This enhancement not only results in improved image quality but also brings us closer to generating more realistic and detailed visuals. You can try it out on clipdrop!
Mind to Image
Yes, you read that right! The Authors of DreamDiffusion Paper have trained a Mind to Image Model, with which they can generate images using the EEG signals. They follow up the Brain2Image Model and present new techniques to train such a model. You can read more here.
While the development of Mind to Image models is still in its early stages, it represents an exciting frontier in generative AI. As researchers continue to work upon these models, we can expect further advancements that deepen our understanding of the human mind and create exciting opportunities for human-machine interaction!
Text to Music
Imagine being able to create high-quality music simply by describing it in words. Well, now you can do just that with Meta's MusicGen. This innovative tool allows you to generate music based on textual descriptions, bringing your ideas to life in the form of beautiful melodies. Not Only that, But it can also take an example melody as input and generate music conditioned on that.
MusicGen is a direct competitor to Google's MusicLM, which is still in the waitlisting period. While both tools aim to generate music, MusicGen sets itself apart with its versatility and high-quality output. Whether you're looking for upbeat tunes to energize your work sessions or calm and soothing melodies to relax and find inner peace, MusicGen can cater to your needs with its impressive capabilities. And the best part is that it is completely Open Source! Try it out for yourself!
Prompt Free Diffusion
The performance of Text2Image is largely dependent on text prompts. In Prompt-Free Diffusion, no prompt is needed, just reference images! As they say that a Picture is worth a thousand words, you can now get much more finetuned generations by using reference images instead of textual prompts. At the core of Prompt-Free Diffusion is an image-only semantic context encoder (SeeCoder). SeeCoder is reusable to most CLIP-based T2I models: just drop in and replace CLIP, then you will create your own prompt-free diffusion.
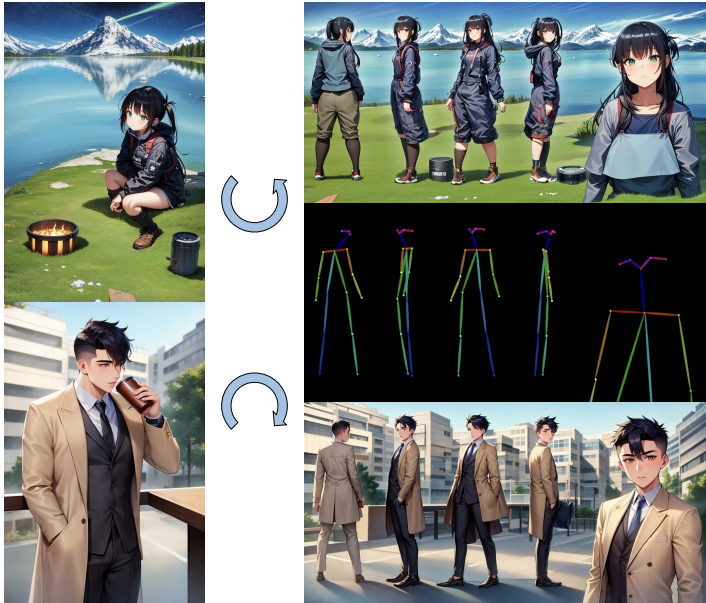
Demo of anime figure generation using Prompt-Free Diffusion with a reference image and conditioning pose.
The ability to drop in this component in place of clip makes it highly versatile for usage with models which use Stable Diffusion or ControlNet Models as Base. This can be used for various applications like Virtual Try On, which requires special training of Two U-Nets for high Quality Generation.

Try On Diffusion
The Efficient deployibility and it’s recent integration with AUTOMATIC1111’s WebUI makes it a very usable component which gives the traditional Text to Image Models a new dimension. It’s available as a Space on Huggingface!
Point based Editing

DragGAN empowers users with unprecedented control over image deformations. With its precision and ability to produce realistic outputs, it surpasses previous approaches in the tasks of image manipulation and point tracking. Whether you want to alter the pose of an animal, reshape a car, change the expression of a person, or transform a landscape, DragGAN allows you to do so with ease. What's even better is that it is now completely Open Source, with a HuggingFace demo that you can go Check out!
Text to Video
Any Discussion of Generative Models is incomplete without the discussion of text-to-video models. Now that Midjourney, DALL-E, Stable Diffusion and its countless variations seem to have perfected Text to Image, Text to Video still has a long way to go.
Runway’s Gen2 seemed to be the only contender for the past few months but with the release of Cerspense’s Zeroscope v2 model, the text to video scene has stirred up. The emergence of Zeroscope v2 has sparked interest and curiosity among researchers, developers, and enthusiasts. People are eager to explore its features, compare its performance to existing models, and see how it can enhance the text-to-video generation process. Try it here!
While text-to-image models have made remarkable strides, text-to-video models are still a work in progress. The development of robust and high-quality text-to-video models is an ongoing research area, and it will take time to perfect the process of generating videos directly from textual descriptions. Nonetheless, with continued advancements and research efforts, we can look forward to a future where generating videos from text becomes as seamless and impressive as generating images.
Conclusion
The progress made in text to image generation is just the tip of the iceberg for Generative AI. Exciting Developments in other areas like Text to 3D with DreamFusion and DreamHuman, Or Image Based Editing with Paint by Example highlight that there are still many avenues for improvement and innovation. Recent Advancements in Text to Speech with Meta’s MMS, that allow for generation in 1000+ languages, Or AudioPaLM for Speech to Speech Translation, showcase that areas which felt saturated still have improvements coming and the future holds great potential for generative AI, promising a world where creativity, communication, and accessibility are further empowered by these transformative technologies.
Comments
Post a Comment